メモリは知識ではない
AIエージェントにはメモリがある——しかしメモリは知識ではない。GoClawには3層のメモリがある:ワーキング → エピソード → セマンティック。しかし、エージェントが特定のドキュメントを見つけたり、ファイル間の相互参照をしたり、ドキュメントの関係をトラッキングする必要がある場合——メモリシステムでは不十分。
検索の断片化——各ストアを個別にクエリする必要
ドキュメント関係なし——バックリンクが存在しない
古いコンテンツ——外部編集がDBに同期されない
Knowledge Vaultは3つすべてを解決:ドキュメントレジストリ + ウィキリンク + ハイブリッド検索 + ファイルシステム同期。
メモリシステムの上位クエリレイヤー
| Component | 役割 |
|---|---|
| VaultStore | ドキュメントCRUD、リンク管理、ハイブリッド検索(FTS + ベクター) |
| VaultSearchService | 検索コーディネーター:vault、エピソード、KG全体の並列ファンアウト |
| EnrichWorker | 5フェーズ非同期パイプライン:準備 → 要約 → 埋め込み → 分類 → ウィキリンク |
| VaultSyncWorker | ファイルシステムウォッチャー:変更を検出、コンテンツハッシュを同期 |
| VaultInterceptor | ファイル操作にフック:エージェント書き込み時に自動登録 |
| VaultRetriever | vault検索をエージェントL0メモリにブリッジ |
書き込みパス
読み込みパス
テナント&スコープ分離
各ドキュメントはスコープに属する:personal(エージェントのみ)、team(チームワークスペース)、shared(クロスエージェント、未実装)。テナントAのドキュメントはテナントBと完全に分離——リンクもテナントを越えられない。パーソナルドキュメントはチームドキュメントにリンク可能。
vault_documents + vault_links
ドキュメントレジストリ:メタデータポインタ。コンテンツはファイルシステムに保存;DBはパス、ハッシュ、埋め込みを保持。
インデックス
HNSW(階層型ナビゲーション可能スモールワールド、m=16、ef=64)——意味的に類似したドキュメントを見つけるための専用ベクター検索インデックス。GIN(汎用転置インデックス)——キーワードマッチング用全文検索インデックス。
vault_links
7種類のリンク:wikilink([[...]]から自動)、reference、depends_on、extends、related、supersedes、contradicts。セマンティックリンクはLLMにより分類。
双方向[[リンク]]
[[target]]形式の双方向Markdownリンク——ObsidianやNotionのように。
解決戦略
GetDocument(tenantID, agentID, target).md suffixpath_basename同期戦略
SyncDocLinks()——置換戦略:[[...]]を抽出 → 古い送信ウィキリンクを削除 → ターゲットを解決 → 新規一括作成。セマンティックリンク(LLM分類)は影響を受けない。
FTS + ベクター + クロスストアファンアウト
なぜ「ハイブリッド」が必要?
エージェントが「ユーザー認証」を検索する場合:FTSは正確なキーワードを見つけるが異なる用語(「ログインフロー」)を使うドキュメントを見逃す。ベクター検索は意味の同等性を理解するが、緩く関連する結果を返すことがある。組み合わせ:FTSは精度、ベクターは再現率。
ステップ1:Vault内のFTS + ベクター
ステップ2:3ソース間のファンアウト
グレースフルデグラデーション:ストアがnil → スキップ。
オーバーシューティング:各ストアがmaxResults*2を返す。
チームコンテキスト:RunContextから——スプーフィング防止。
5フェーズ非同期ワーカー
ドキュメントが書き込まれても、検索-readyではない。EnrichWorkerが5フェーズを通じて処理し、検索可能にする。
重複チェック(docID + ハッシュ)→ メタデータ一括取得 → ファイル読み込み(最大4MB)→ すでに要約済みのドキュメントをフィルタ。
5ドキュメントを1つのLLM呼び出しにパック。温度0.2、最大1536トークン。JSON出力:[{"idx":1,"summary":"..."}]。LLM呼び出しを5倍削減。
タイトル + パス + 要約を結合 → 1536次元埋め込みベクター。テキストを意味空間の座標に変換。
FindSimilarDocs(コサイン ≥ 0.7)→ LLMが6種類のリンクタイプに分類。温度0.1。意味のある関係がない場合はSKIPを出力。
[[...]]を抽出 → ターゲットを解決 → 古いウィキリンクを削除 → 新規一括作成。重複除外マップは10Kエントリに制限、25%をエビクト。
チューニング定数
リトライ:段階的タイムアウト5→7→10分、バックオフ0→2→4秒。BatchQueue:テナント:エージェントごとのロックフリーproducer-consumer——再スキャン時のサウンディングハードを防止。
ワークスペースの同期と保護
エージェントがファイルを書き込むが、外部から変更される可能性がある(ユーザー編集、git pull)。Vaultには3つの同期メカニズムがある:
fsnotifyがワークスペースを監視。デバウンス500ms → SHA-256 → DBと比較 → 変更時にEnrichWorkerをトリガー。登録済みドキュメントのみ同期。
ワークスペース全体を walk、制限あり:5Kファイル、合計500MB、ファイルあたり50MB。シンボリックリンク、node_modules、.gitをスキップ。パストラバーサルをブロック。
VaultInterceptor.BeforeRead()——エージェントのファイル読み込み時に、FSハッシュとDBをチェック。ウォッチャーが実行されていなくても外部編集をキャッチ。
所有権推論
エージェントコンテキストに自動注入
VaultRetrieverはエージェントが考える前に関連ドキュメントを自動的にコンテキストに注入——手動のvault_searchは不要。
ユーザーが「認証の設定方法」を尋ねる → vaultがdocs/auth.md(スコア0.92)+ SOUL.md(スコア0.45)を自動注入 → より正確な回答。
実世界のアプリケーション
エージェントがメモを書き、[[wikilinks]]で相互参照。Vaultはリンクを自動検出し、バックリンクを作成、コンテンツをインデックス。
パーソナルドキュメントはエージェントのみ表示可能。チームドキュメントは全メンバーが検索可能。パーソナルはチームドキュメントに[[link]]可能。
VaultRetrieverはエージェントが応答する前に関連ドキュメントを自動注入。
ダッシュボードを開いて、すぐに使用
Knowledge Vaultはセットアップ不要——ダッシュボードを開いてすぐに始められる。
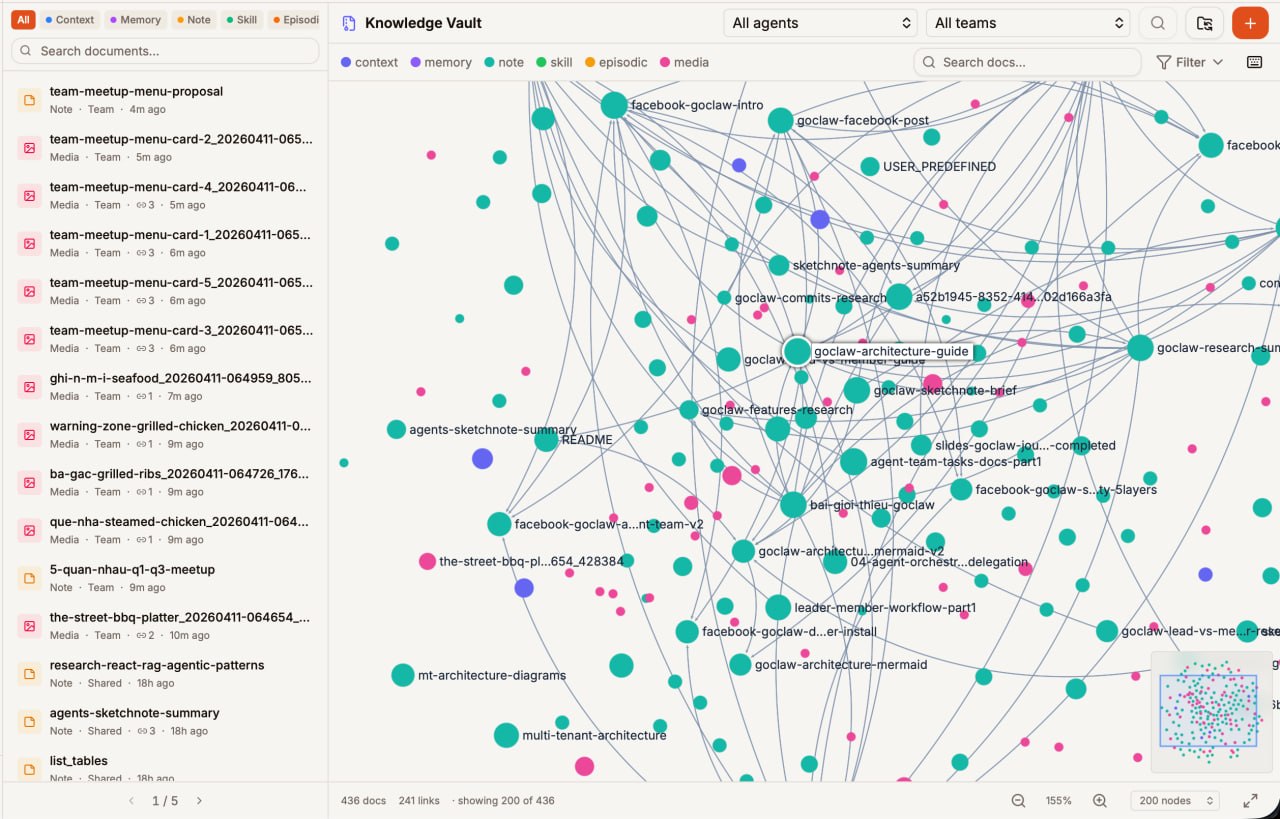
Knowledge Vaultを開く
左サイドバー → Vault(DATAセクション)。2パネルUI:ドキュメントリスト(左)+ ナレッジグラフ可視化(右)。タイプフィルターチップ + エージェント/チームドロップダウン。
ドキュメントをアップロード
+(右上)をクリック → 「Upload to Vault」ダイアログ → 宛先を選択(共有/エージェント/チーム)→ ドラッグ&ドロップまたはファイルを選択(.md、.txt、.json、.yaml、.csvなど)→ アップロード。豊富な処理は自動実行。
ワークスペースを再スキャン(オプション)
Rescan workspaceボタン(+ボタンの隣)をクリック → ワークスペースをスキャン、新しい/変更されたファイルを検出し、スコープ(personal/team/shared)を自動推論。
探索、グラフ&検索
サイドバーでタイプ別にドキュメントを閲覧。右パネルにナレッジグラフ——パン/ズームして関係を探索。統合検索用検索バー。詳細パネルで手動リンクを作成。エージェントはvaultを自動使用。
vault_search
エージェントはvaultと対話するための1つのツールのみを持つ。全知識源を横断する統合検索。
| Param | Type | Required | 説明 |
|---|---|---|---|
query | string | ✓ | 自然言語検索クエリ |
scope | string | フィルター:personal、team、shared(デフォルト:all) | |
types | string | カンマ区切り:context、memory、note、skill、episodic(デフォルト:all) | |
maxResults | number | 最大結果数(デフォルト:10) |
HTTPエンドポイント
Documents
| Method | Endpoint | 機能 |
|---|---|---|
GET | /v1/vault/documents | ドキュメント一覧(フィルター:scope、doc_type、team_id) |
POST | /v1/vault/documents | 新規ドキュメント作成 |
GET | /v1/vault/documents/{docID} | ドキュメント詳細取得 |
PUT | /v1/vault/documents/{docID} | メタデータ更新 |
DELETE | /v1/vault/documents/{docID} | ドキュメント削除 |
Links
| Method | Endpoint | 機能 |
|---|---|---|
GET | .../{docID}/links | Outbound + backlinks |
POST | /v1/vault/links | リンク作成(from、to、type、context) |
DELETE | /v1/vault/links/{linkID} | リンク削除 |
POST | /v1/vault/links/batch | 複数のドキュメントIDのリンクを一括取得 |
検索と運用
| Method | Endpoint | 機能 |
|---|---|---|
POST | /v1/vault/search | Unified cross-store search |
POST | /v1/vault/upload | ファイルアップロード(最大50ファイル、ファイルあたり50MB) |
POST | /v1/vault/rescan | ワークスペースを再スキャン |
GET | ...enrichment-status | 豊富な処理の進行状況(JSON/SSE) |
エージェント別エンドポイント:すべて/v1/agents/{agentID}/vault/...でも利用可能(後方互換)。
同時実行ガード:再スキャンはテナントごとの並列スキャンをブロック。非所有者:パーソナルドキュメント + 自身のチームのみ表示。
4 migrations
| Migration | 内容 |
|---|---|
| 000038 | Initial: vault_documents, vault_links, vault_versions |
| 000042 | summaryを追加、tsvectorを再生成 |
| 000043 | team_id、custom_scopeを追加 |
| 000046 | nullable agent_id、COALESCE制約、自動スコープトリガー |
ファイル参照
| Component | File | 役割 |
|---|---|---|
| Vault service | internal/vault/*.go | 検索コーディネーター、豊富な処理、ウィキリンク、FS walk |
| PG store | internal/store/pg/vault_*.go | ハイブリッド検索(FTS + ベクター)、リンク管理 |
| SQLite store | internal/store/sqlitestore/vault_*.go | ライト版:FTSのみ |
| Tools | internal/tools/vault_*.go | vault_searchツール、VaultInterceptorフック |
| HTTP handlers | internal/http/vault_*.go | REST API、アップロード、再スキャン、豊富な処理の状況 |
| Migrations | migrations/000038-000046 | スキーマの進化(4回のイテレーション) |
設計のトレードオフ
FTS 0.4、ベクター 0.6——ベクターはセマンティックを優先;FTSはキーワード精度を追加。クロスストア 0.4/0.3/0.3——Vaultのキュレーションされたコンテンツを優先。
LLM呼び出しあたり5ドキュメント——スループットと品質のバランス。コサイン 0.7——本当に類似したもののみを分類、ノイズを削減。
nullable agent_id——チームドキュメントはエージェント所有権を必要としない。置換戦略ウィキリンク用——シンプル、冪等。