记忆不是知识
AI 智能体有记忆——但记忆不是知识。GoClaw 已有三层记忆:工作记忆 → 情景记忆 → 语义记忆。但当智能体需要查找具体文档、交叉引用文件、或跟踪文档关系时——记忆系统不够用。
搜索分散——需要分别查询每个存储
没有文档关系——反向链接不存在
内容过期——外部编辑未同步到数据库
Knowledge Vault 解决全部三个问题:文档注册表 + 维基链接 + 混合搜索 + 文件系统同步。
记忆系统之上的查询层
| Component | 角色 |
|---|---|
| VaultStore | 文档 CRUD、链接管理、混合搜索(FTS + 向量) |
| VaultSearchService | 搜索协调器:跨 vault、情景、知识图谱的并行扇出 |
| EnrichWorker | 5 阶段异步管线:准备 → 摘要 → 嵌入 → 分类 → 维基链接 |
| VaultSyncWorker | 文件系统监控:检测变更,同步内容哈希 |
| VaultInterceptor | 挂钩文件操作:智能体写入时自动注册 |
| VaultRetriever | 将 vault 搜索桥接到智能体 L0 记忆 |
写入路径
读取路径
租户与作用域隔离
每个文档属于一个作用域:personal(仅智能体)、team(团队工作区)、shared(跨智能体,尚未实现)。租户 A 的文档与租户 B 完全隔离——即使是链接也不能跨租户。个人文档可以链接到团队文档。
vault_documents + vault_links
文档注册表:元数据指针。内容存储在文件系统;数据库保存路径、哈希、嵌入。
索引
HNSW(分层可导航小世界,m=16,ef=64)——专用于向量搜索的索引,查找语义相似的文档。GIN(广义倒排索引)——全文搜索索引,用于关键字匹配。
vault_links
7 种链接类型:wikilink(自动从 [[...]])、reference、depends_on、extends、related、supersedes、contradicts。语义链接由 LLM 分类。
双向 [[链接]]
使用 [[target]] 格式的双向 Markdown 链接——类似 Obsidian 或 Notion。
解析策略
GetDocument(tenantID, agentID, target).md suffixpath_basename同步策略
SyncDocLinks()——替换策略:提取 [[...]] → 删除旧的传出维基链接 → 解析目标 → 批量创建新链接。语义链接(LLM 分类)不受影响。
FTS + 向量 + 跨存储扇出
为什么需要"混合"?
假设智能体搜索"用户认证":FTS 找到精确关键字但遗漏使用不同术语的文档("登录流程")。向量搜索 理解语义等价但有时返回松散相关的结果。结合使用:FTS 提供精确度,向量提供召回率。
步骤 1:Vault 中的 FTS + 向量
步骤 2:跨 3 个源扇出
优雅降级:存储为 nil → 跳过。
超额返回:每个存储返回 maxResults*2。
团队上下文:来自 RunContext——防止伪造。
5 阶段异步工作器
文档写入后,还不能用于搜索。EnrichWorker 通过 5 个阶段处理使其可搜索。
去重检查(docID + 哈希)→ 批量获取元数据 → 读取文件(最大 4MB)→ 过滤已有摘要的文档。
将 5 个文档打包到 1 个 LLM 调用中。温度 0.2,最大 1536 token。JSON 输出:[{"idx":1,"summary":"..."}]。减少 5 倍 LLM 调用。
拼接标题 + 路径 + 摘要 → 1536 维嵌入向量。将文本转换为语义空间中的坐标。
FindSimilarDocs(余弦 ≥ 0.7)→ LLM 分类为 6 种链接类型。温度 0.1。如果没有有意义的关系,输出 SKIP。
提取 [[...]] → 解析目标 → 删除旧的维基链接 → 批量创建新链接。去重映射上限 10K 条目,驱逐 25%。
调优常量
重试:递增超时 5→7→10 分钟,退避 0→2→4 秒。BatchQueue:每个租户:智能体的无锁生产者-消费者——防止重新扫描时的惊群效应。
同步和保护工作区
智能体写入文件,但它们可能被外部修改(用户编辑、git pull)。Vault 有 3 种同步机制:
fsnotify 监控工作区。防抖 500ms → SHA-256 → 对比数据库 → 变更时触发 EnrichWorker。仅同步已注册的文档。
遍历整个工作区,有限制:5K 文件,总共 500MB,每个文件 50MB。跳过符号链接、node_modules、.git。路径遍历被阻止。
VaultInterceptor.BeforeRead()——智能体读取文件时,检查文件系统哈希与数据库。即使监控器未运行也能捕获外部编辑。
所有权推断
自动注入到智能体上下文
VaultRetriever 在智能体思考前自动将相关文档注入上下文——不需要手动调用 vault_search。
用户问"如何设置认证" → vault 自动注入 docs/auth.md(得分 0.92)+ SOUL.md(得分 0.45)→ 更准确的回答。
实际应用场景
智能体写笔记,使用 [[wikilinks]] 交叉引用。Vault 自动检测链接、创建反向链接、索引内容。
个人文档仅智能体可见。团队文档所有成员可搜索。个人可以 [[link]] 到团队文档。
VaultRetriever 在智能体回答前自动注入相关文档。
打开仪表板,立即使用
Knowledge Vault 无需设置——打开仪表板即可开始。
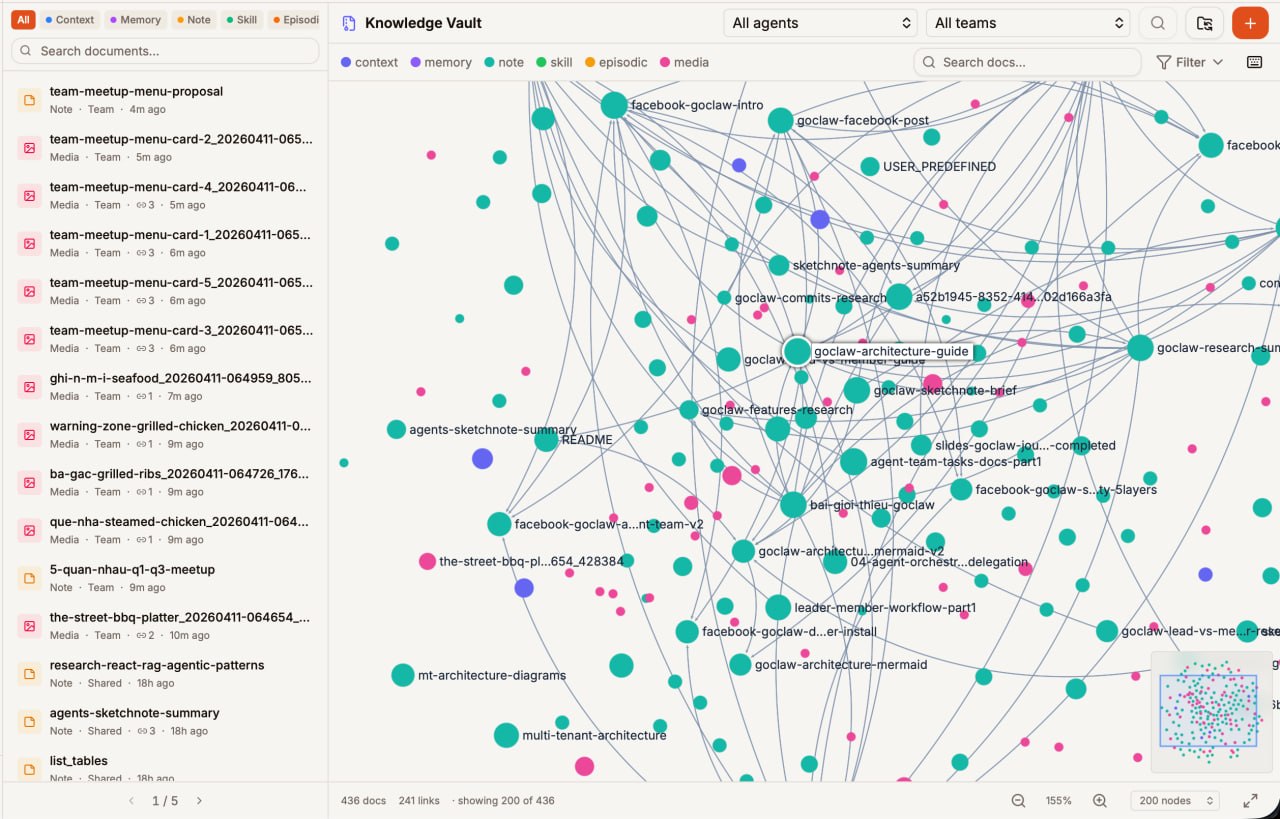
打开 Knowledge Vault
左侧边栏 → Vault(DATA 部分)。双面板 UI:文档列表(左)+ 知识图谱可视化(右)。类型筛选芯片 + 智能体/团队下拉菜单。
上传文档
点击 +(右上)→ "上传到 Vault" 对话框 → 选择目标(共享/智能体/团队)→ 拖放或浏览文件(.md、.txt、.json、.yaml、.csv 等)→ 上传。丰富处理自动运行。
重新扫描工作区(可选)
点击 重新扫描工作区(+ 按钮旁边)→ 扫描工作区,检测新/变更文件,自动推断作用域(个人/团队/共享)。
探索、图谱和搜索
边栏按类型浏览文档。右侧面板显示知识图谱——平移/缩放探索关系。搜索栏用于统一搜索。在详情面板创建手动链接。智能体自动使用 vault。
vault_search — 唯一的工具
智能体只有 1 个工具与 vault 交互。跨所有知识源的统一搜索。
| Param | Type | Required | 描述 |
|---|---|---|---|
query | string | ✓ | 自然语言搜索查询 |
scope | string | 筛选:personal、team、shared(默认:all) | |
types | string | 逗号分隔:context、memory、note、skill、episodic(默认:all) | |
maxResults | number | 最大结果数(默认:10) |
HTTP 端点
Documents
| Method | Endpoint | 功能 |
|---|---|---|
GET | /v1/vault/documents | 文档列表(筛选:scope、doc_type、team_id) |
POST | /v1/vault/documents | 创建新文档 |
GET | /v1/vault/documents/{docID} | 获取文档详情 |
PUT | /v1/vault/documents/{docID} | 更新元数据 |
DELETE | /v1/vault/documents/{docID} | 删除文档 |
Links
| Method | Endpoint | 功能 |
|---|---|---|
GET | .../{docID}/links | Outbound + backlinks |
POST | /v1/vault/links | 创建链接(from、to、type、context) |
DELETE | /v1/vault/links/{linkID} | 删除链接 |
POST | /v1/vault/links/batch | 批量获取多个文档 ID 的链接 |
搜索和运维
| Method | Endpoint | 功能 |
|---|---|---|
POST | /v1/vault/search | Unified cross-store search |
POST | /v1/vault/upload | 上传文件(最多 50 个文件,每个 50MB) |
POST | /v1/vault/rescan | 重新扫描工作区 |
GET | ...enrichment-status | 丰富处理进度(JSON/SSE) |
每个智能体端点:所有端点也有 /v1/agents/{agentID}/vault/... 作用域版本(向后兼容)。
并发保护:重新扫描阻止每个租户的并行扫描。非所有者:只能看到个人文档和自己的团队。
4 migrations
| Migration | 内容 |
|---|---|
| 000038 | Initial: vault_documents, vault_links, vault_versions |
| 000042 | 添加 summary,重新生成 tsvector |
| 000043 | 添加 team_id、custom_scope |
| 000046 | 可空 agent_id、COALESCE 约束、自动作用域触发器 |
文件参考
| Component | File | 角色 |
|---|---|---|
| Vault service | internal/vault/*.go | 搜索协调器、丰富处理、维基链接、文件系统遍历 |
| PG store | internal/store/pg/vault_*.go | 混合搜索(FTS + 向量)、链接管理 |
| SQLite store | internal/store/sqlitestore/vault_*.go | 精简版:仅 FTS |
| Tools | internal/tools/vault_*.go | vault_search 工具、VaultInterceptor 挂钩 |
| HTTP handlers | internal/http/vault_*.go | REST API、上传、重新扫描、丰富处理状态 |
| Migrations | migrations/000038-000046 | 架构演进(4 次迭代) |
设计权衡
FTS 0.4,向量 0.6——向量优先语义;FTS 补充关键字精确度。跨存储 0.4/0.3/0.3——Vault 精选内容优先。
每个 LLM 调用 5 个文档——平衡吞吐量与质量。余弦 0.7——仅分类真正相似的文档,减少噪声。
可空 agent_id——团队文档不需要智能体所有权。替换策略用于维基链接——简单、幂等。